Входной учет компонентов. Демонстрация возможностей ISM Incoming Material Station
Станция может использоваться как в составе данного комплексного решения, так и как отдельный самостоятельный продукт для произведения автоматической регистрации всех поступающих на склад компонентов и внесения корректных данных в базу данных предприятия. Таким образом, используя станцию ISM Incoming Material Station, мы упрощаем и ускоряем процесс регистрации всех поступающих на склад компонентов.
Типовой процесс регистрации компонентов предусматривает ввод информации с этикетки вручную. Это означает, что оператор самостоятельно анализирует информацию, в частности такую как название компонента и количество компонентов катушки, и переносит эту информацию в базу данных складской системы предприятия. Такой подход занимает много времени и ведет к неизбежным ошибкам, особенно в случае регистрации большого количества катушек, поступивших на склад.
Применяя же систему регистрации компонентов достаточно расположить катушку на прозрачном стекле, далее всю процедуру по анализу изображения этикетки и переносе информации в базу данных система выполняет автоматически. Оператору остается лишь наклеить этикетку с уникальным номером катушки на ее верхнюю плоскость (Рисунок 1).

Рисунок 1
Состав станции
В состав станции регистрация компонентов ISM Incoming Material Station входит рабочий стол со встроенным прозрачным окном, где у нас располагается камера, распознающая информацию с этикеток, монитор, где мы видим интерфейс управляющего ПО, встроенный сканер 1D и 2D кодов, настольный принтер для распечатывания этикеток с уникальным номером катушек, а также имеется клавиатура и мышь для управления ПО. Опционально станция регистрации компонентов может оснащаться вторым монитором для осуществления сверки информации, поступающей из ERP-системы либо из заказ-наряда.
Внутри рабочего стола имеется управляющий компьютер и встроенная в рабочий стол камера, которая смотрит на регистрируемые катушки снизу-вверх.
Процесс регистрации катушки
Рассмотрим процесс регистрации катушки в базе данных предприятия. Катушка, на которой имеется этикетка с информацией от производителя, располагается этикеткой вниз на прозрачном столе. Встроенная камера смотрит на этикетку, анализирует информацию с нее и автоматически переносит эту информацию в поля ввода, необходимые для регистрации компонентов. После этого можно подтвердить процедуру и распечатать наклейку с уникальным номером катушки, которая уже дальше будет использоваться для прослеживаемости при работе с данной катушкой.
То есть система считала всю информацию автоматически: номер компонента, количество со штрих-кода. Далее оператор нажимает сохранить и производится распечатывание этикетки с уникальным номером. Уникальный номер начинается с «А» и цифрового обозначения, и эта этикетка наклеивается на катушку. После система позволит автоматически перепроверить, правильно ли наклеена этикетка. То есть производится повторное считывание не только информации с наклейки от производителя, но также и с распечатанной и наклеенной этикетки. Если информация соответствует тому что требуется, то система принимает данный факт и компонент регистрируются в базе данных.
Рассмотрим, как это выглядит в программном обеспечении. Катушка располагается на прозрачном стекле, нажимается кнопка автораспознавание, система способна считать все штрих-коды, нанесенные на этикетку, и перенести их информацию в соответствующие поля ввода (Рисунок 2). Также система может автоматически сопоставлять название от производителя с названием компонента, использованного на предприятии. Они могут отличаться. После этого идет процедура распечатывания наклейки с уникальным номером и оператор наклеивает ее на катушку.
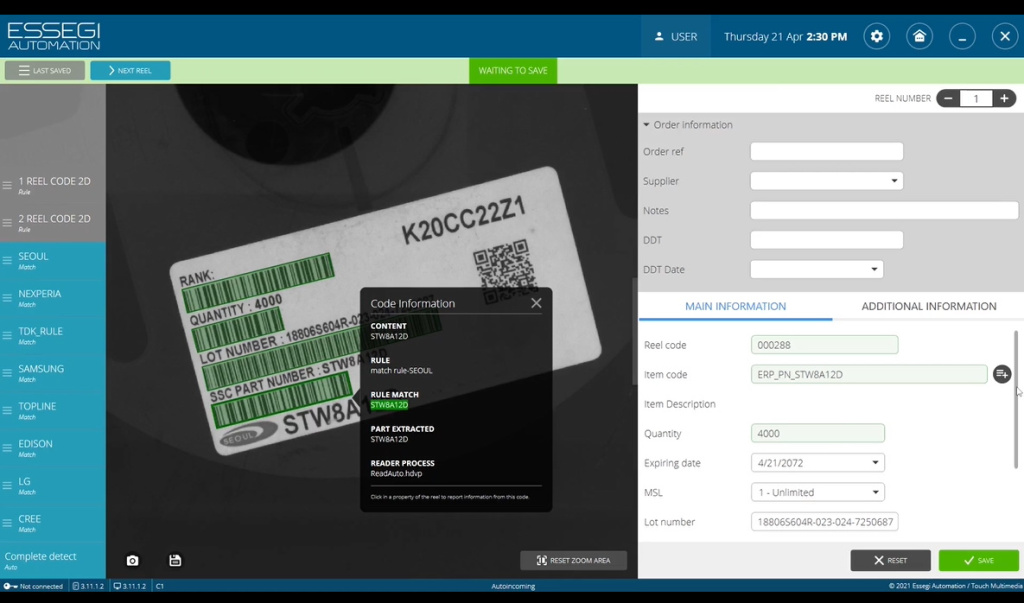
Рисунок 2
Далее располагается следующая катушка, нажимается кнопка автораспознавания, аналогичная информация автоматически считывается, переносится в поля ввода с присвоением нового уникального номера катушки. После этого оператор нажимает кнопку сохранить и катушка регистрируется в системе.
Верификация этикеток с уникальным номером катушки
Рассмотрим работу функции верификации этикеток с уникальным номером катушки. Для этого катушка располагается на прозрачном стекле, нажимается кнопка автораспознавания, система считывает информацию штрих-кодах и переносит в соответствующие поля ввода. В данном случае ряд полей подсвечен красным цветом, это означает, что работает функции верификации, то есть требуется после распечатывания этикетки с уникальным номером катушки повторно данную катушку расположить на прозрачном стекле и нажать на кнопку автораспознавание. Система считывает информацию же с обеих этикеток и сверяет ее. Нужно правильное соответствие свежеприсвоенного номера катушки с названием компонента, нанесенного на этикетку от производителя. Таким образом данная функция позволяет избежать ошибок оператора при наклеивании этикеток с уникальным номером катушки.
Возможности считывания информации с различных этикеток
Какая информация может быть нанесена на этикетку? Информация может быть в виде штрих-кодов, причем этих штрих-кодов может быть несколько. Есть штрих-коды, отвечающие, например, за количество компонентов катушки, есть штрих-код, который отвечает за название, за номер компонента, дополнительно может быть транспортный номер и дополнительная информация. В ряде случаев также вся необходимая информация может быть зашифрована производителем в qr-коде. То есть в одном qr-коде содержится информация как о количестве, так и о названии компонентов.
Бывают нестандартные катушки, где штрих-коды отсутствует и есть только символы. По сути название и количество непосредственно напечатаны на этикетку. Система позволяет это считывать при помощи метода OCR, то есть система может не только считывать штрих-коды, 2D-коды, qr-коды, но и считывать цифробуквенную информацию, благодаря возможности встроенного программного распознавания различных символов.
Создание правил импорта информации с этикетов с 1D кодами
Как же система считывает информацию с этикеток? Рассмотрим пример. На Рисунке 3 этикета содержит штрих-коды и мы можем зайти в библиотеку правил, которая имеется в настройках.
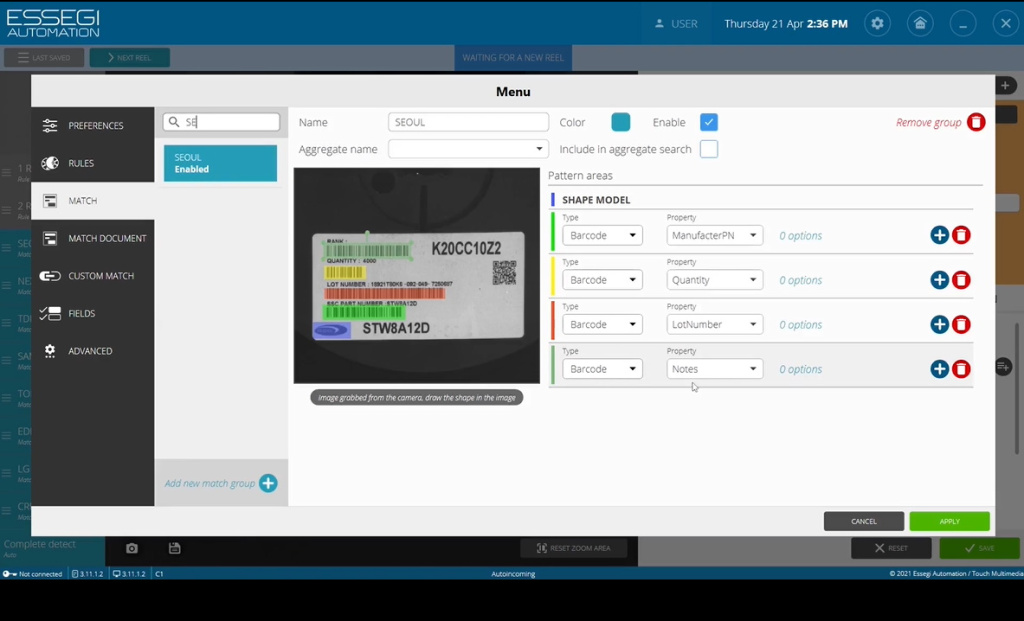
Рисунок 3
В данном случае это правила SEOUL. Что же из себя представляют правила? Правила - это некие поля поиска, в которых система ищет и считывает необходимую информацию, например, в данном случае на Рисунке 3 в красном считывается lot number, в зеленом поле считывается manufacturer part number, то есть название от производителя, в синем поле считывается некий реперный элемент - это может быть логотип компании, относительно которого ищутся все остальные поля поиска.
Мы также можем создать новое поле поиска, в котором хотим считать какую-либо информацию. Для этого указываем поле, указываем метод, каким мы хотим считывать, после этого мы указываем куда отнести эту считанную информацию, например, это может быть Part number, то есть номер компонента. После внесения необходимых правок нажимаем кнопку APPLY (сохранить) и можем данное правило использовать при считывании информации. Нажимаем на кнопку правило, информация считывается, на Рисунке 4 мы видим, что все подсвечена зеленым, то есть это означает, что правила считали необходимую информацию.
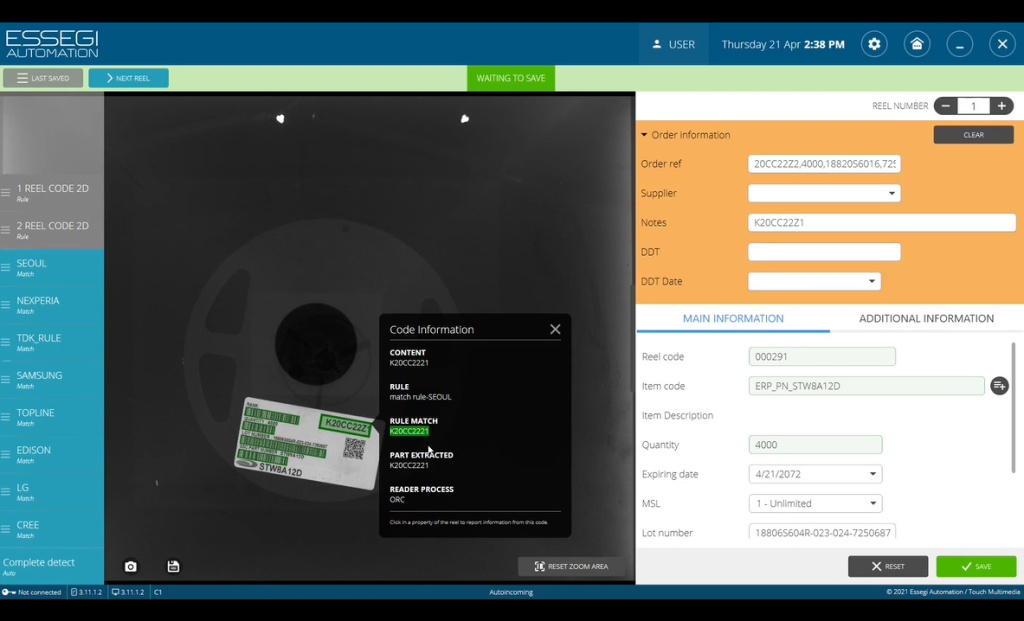
Рисунок 4
Работа с одним штрих-кодом
Рассмотрим создание собственного правила импорта. Для этого возьмем пример этикетки от компании LG (Рисунок 5). На ней нанесен один штрих-код, в котором зашифрован не только номер название компонента, но и дополнительная информация. Информация в данном случае разделена знаками равенства. Нажимаем на кнопку Complete detect, попробуем считать информацию в данном штрих-коде. Поле подсветилось оранжевым цветом (Рисунок 6), видим, что все что считалось соответствует тому, что нанесено штрих-кодом.
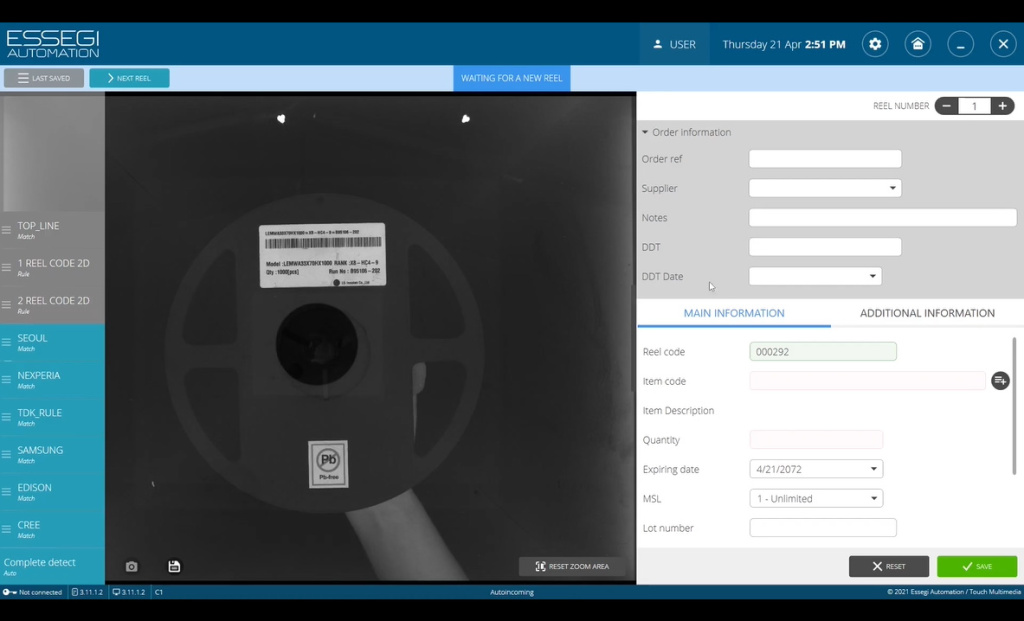
Рисунок 5
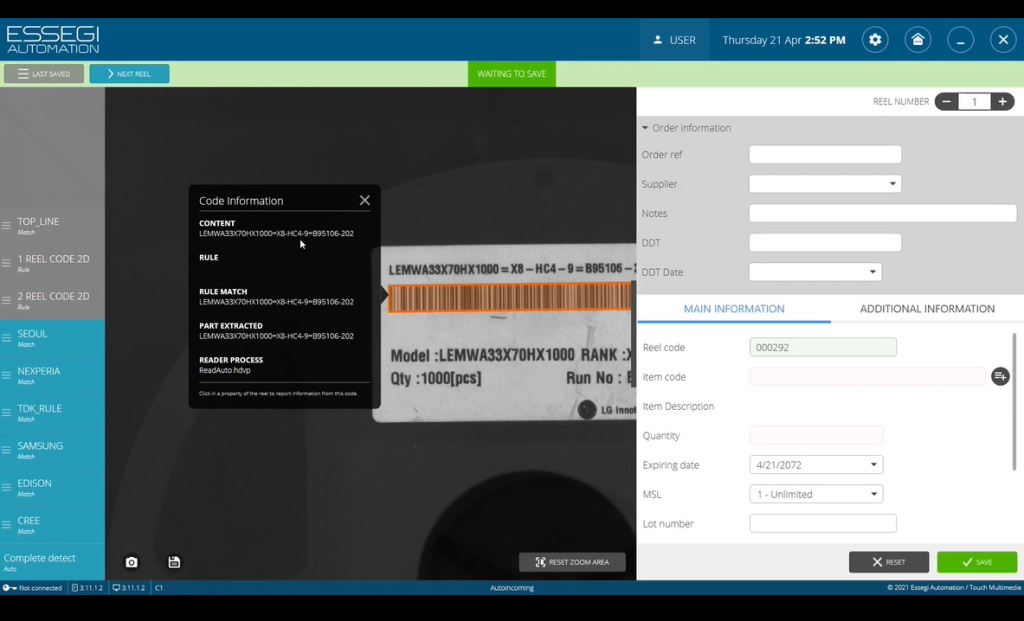
Рисунок 6
Как создать правило? Заходим в «Настройки», в библиотеку правил, нажимаем кнопку «Создать новое правило», даем этому правилу имя, например, правило будет называться в данном случае LG_MATCH (это правило импорта информации с этикетки от производителя). Уже после этого на изображении определяем область, где содержится этикетка и на данной области мы задаем некий реперный элемент. Это может быть, к примеру, логотип компании. Относительно этого элемента и будут искаться остальные поля анализа, которые мы также указываем. В данном случае зеленое поле будет считывать штрихкод, в котором содержится информация, как о количестве, так и дополнительная формация, которую можно отнести к заметкам Notes. В случае отсутствия информации о количестве необходимо считать символы в дополнительном поле – желтом, при помощи метода OCR (Рисунок 7).
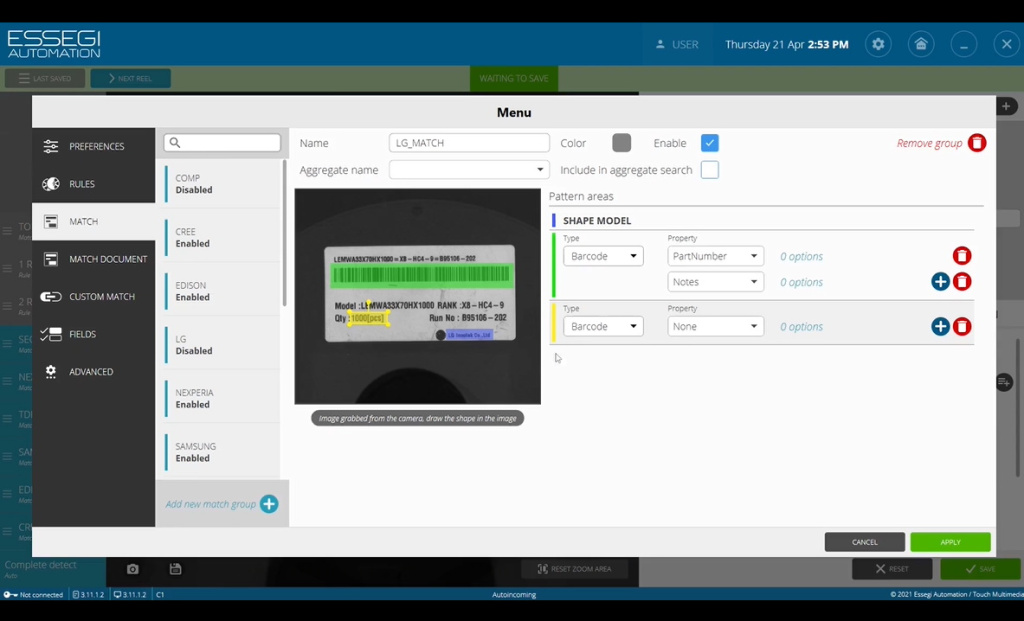
Рисунок 7
OCR — это метод, который позволяет считывать символьную информацию и переводить ее в текст. Указываем, что считываемая информация будет относиться к quantity (количеству) и приступаем к фильтрации информации из считываемой строки. То есть считываемая строка в штрих-коде содержит сразу много информации, мы должны отфильтровать название компонента. Для этого применим опцию импорта, метод RemoveFromChars. Этот метод позволяет удалить из считываемой строки определенные символы с определенного индекса. Это будет соответствовать названию нашего компонента. Применительно к заметкам Notes мы также используем опцию извлечения, то есть опцию импорта информации. Применяем метод RemoveFirstChars, который позволяет удалить первые символы, то есть в защитной строке удалять первые 26 символов и оставлять оставшиеся. Так же мы применим дополнительные опции к Quantity, то есть к количеству. Здесь мы используем метод Replace и будем заменять считанные скобки и символы PCS на пустую строку. То есть будем оставлять только цифровую информацию, которая будет соответствовать количеству компонентов. Указываем цвет нашего правила и нажимаем кнопку APPLY (сохранить), как показано на Рисунке 8.
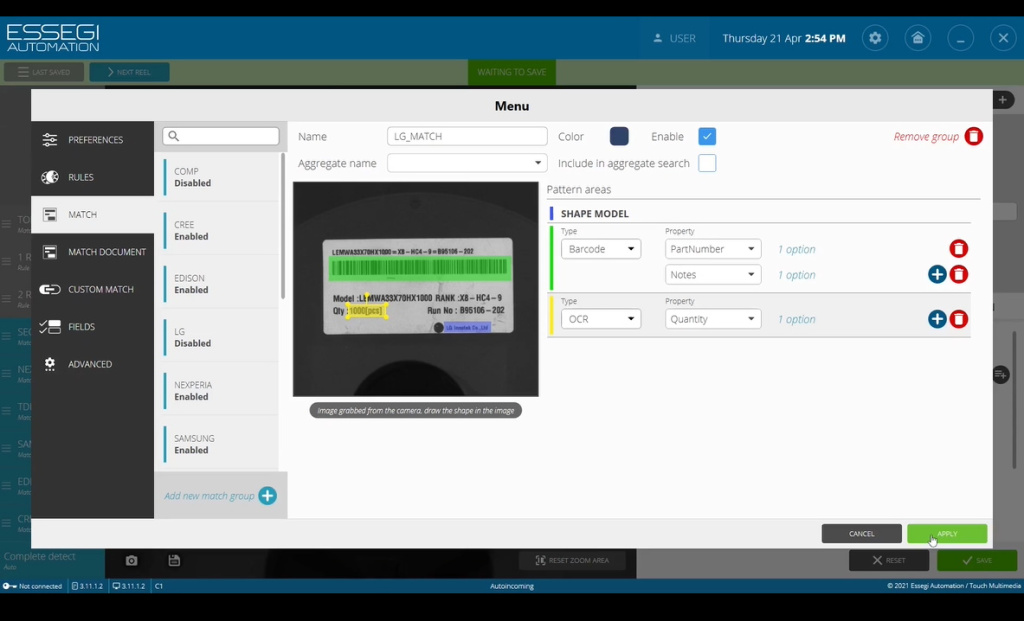
Рисунок 8
После этого в интерфейсе программы появится новая кнопка с названием LG_MATCH (Рисунок 9), и данную кнопку будем использовать для анализа нашей этикетки. Нажимаем кнопку, видим что считалось и отфильтровалась информация с названием компонента и с заметками, а также считалась информация о количестве. На экране мы видим название этого компонента, которое имеется в начале считываемой строки и количество без символов PCS, и заметки, которые имелись в штрих-коде.
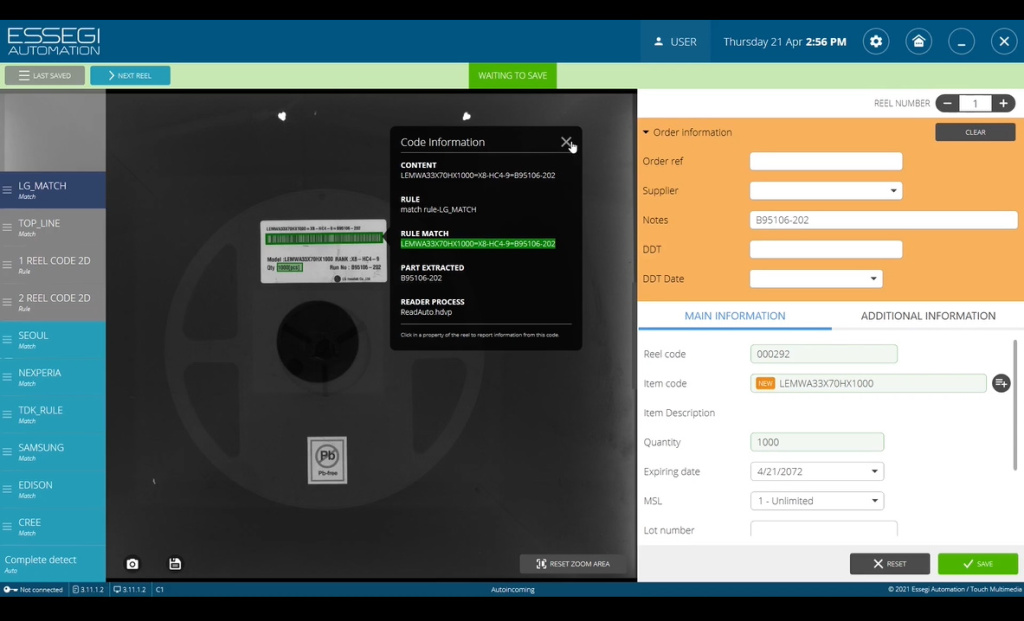
Рисунок 9
Пример работы с функцией OCR
Рассмотрим еще один пример на базе этикетки не содержащей штрих-кодов с информации. То есть содержится только цифробуквенная информация в виде нанесенных символов (Рисунок 10), и мы эту информацию можем также успешно считывать.
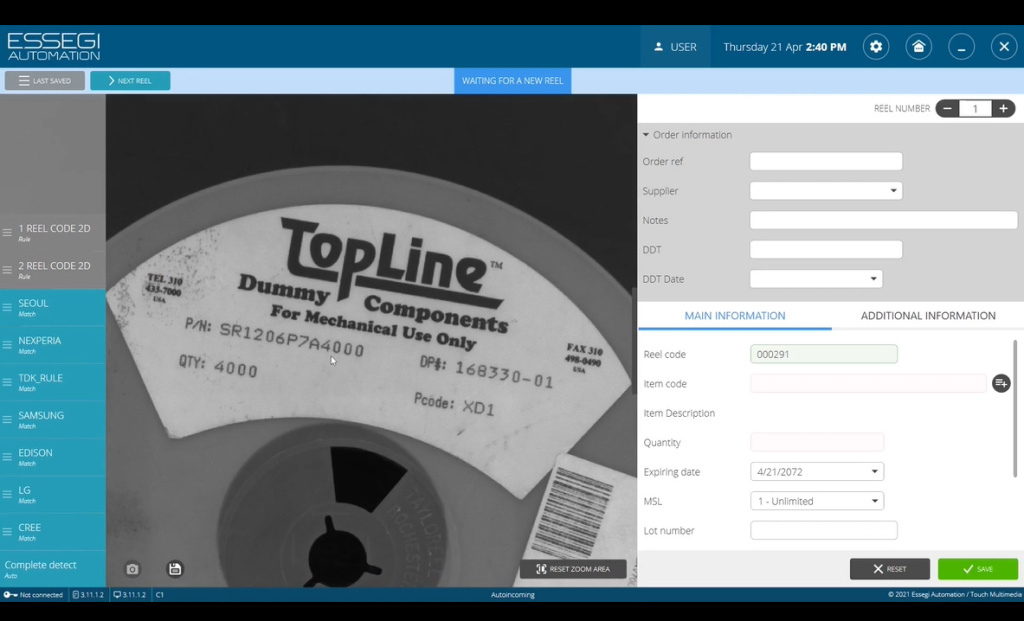
Рисунок 10
Для этого заходим в библиотеку правил, создаем новое правило, даем название, например, в данном случае TOP_LINE, выбираем область изображения, где у нас располагается этикетка, и видим, что у нас на этикетку нанесен Part number (название) и Quantity (Рисунок 11).
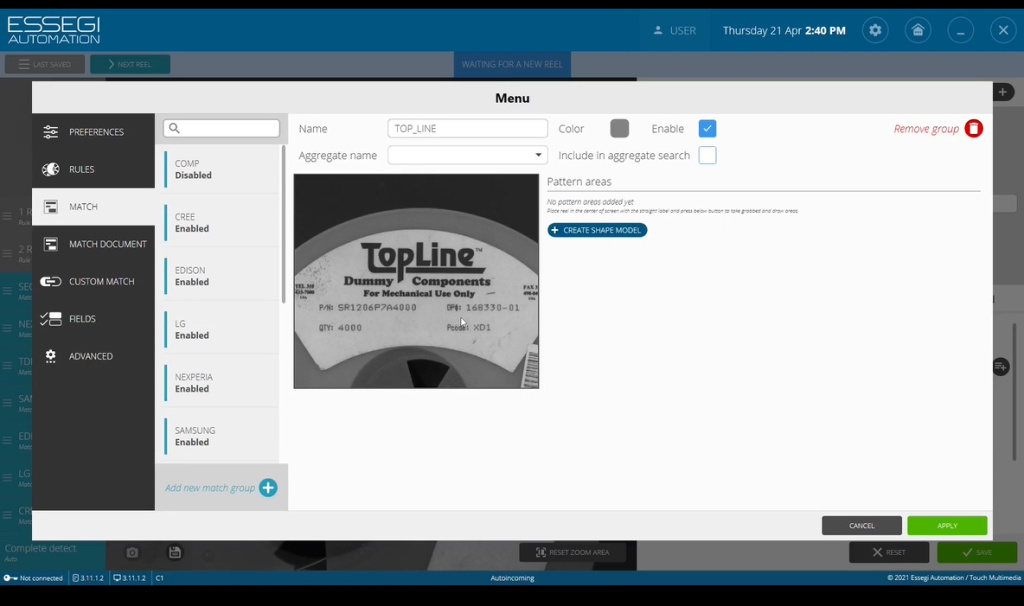
Рисунок 11
Это базовая информация, которую необходимо считать. Определяем реперный элемент - это может быть либо логотип компании, либо часть какого-то названия. Относительно этого реперного элемента ищутся поля анализа. Определяем зеленое поле, это в данном случае поле анализа и считывания названия корпуса компонента, метод считывания OCR. То есть мы будем распознавать цифробуквенную информацию и переводить ее в текст. Определяем следующие желтое поле. Это поле будет содержать информацию о количестве компонентов. Мы также можем определить какие-то дополнительные поля, если требуется, например, создать дополнительно красное поле и считать информацию также методом OCR, например, в виде заметок (Notes)(Рисунок 12).
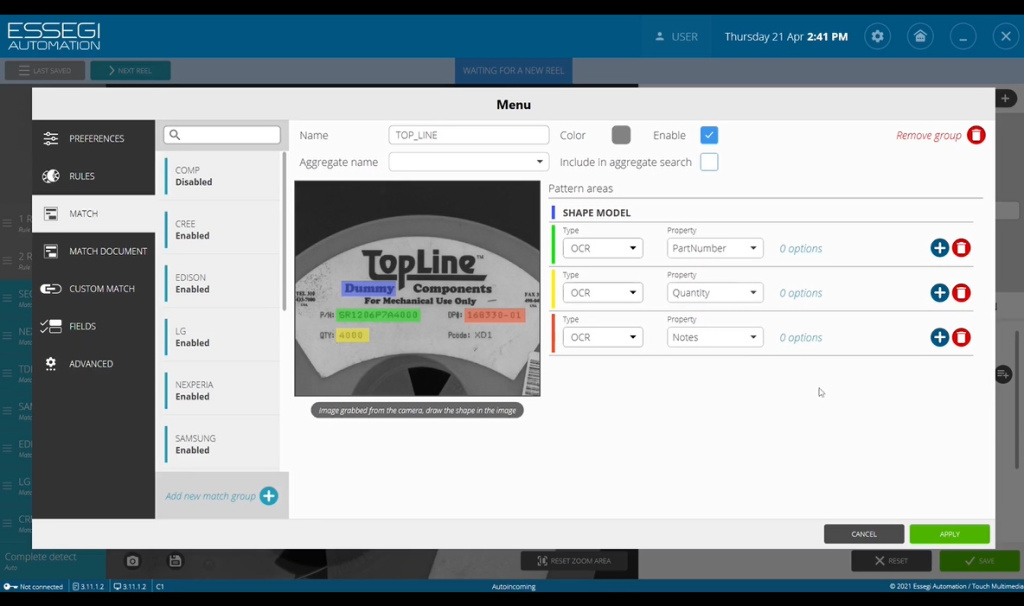
Рисунок 12
Нажимаем кнопку APPLY, появляется новая кнопка с названием Top_line в интерфейсе программы, нажимаем на нее и система пытается считать согласно указанным правилам информацию этикетки. На Рисунке 13 мы видим, что информация считалась, то есть считался номер названия компонента, считалось количество, считались дополнительные заметки. Вся считываемая информация перенеслась автоматически в соответствующие поля ввода, необходимые для регистрации катушки в базе данных.
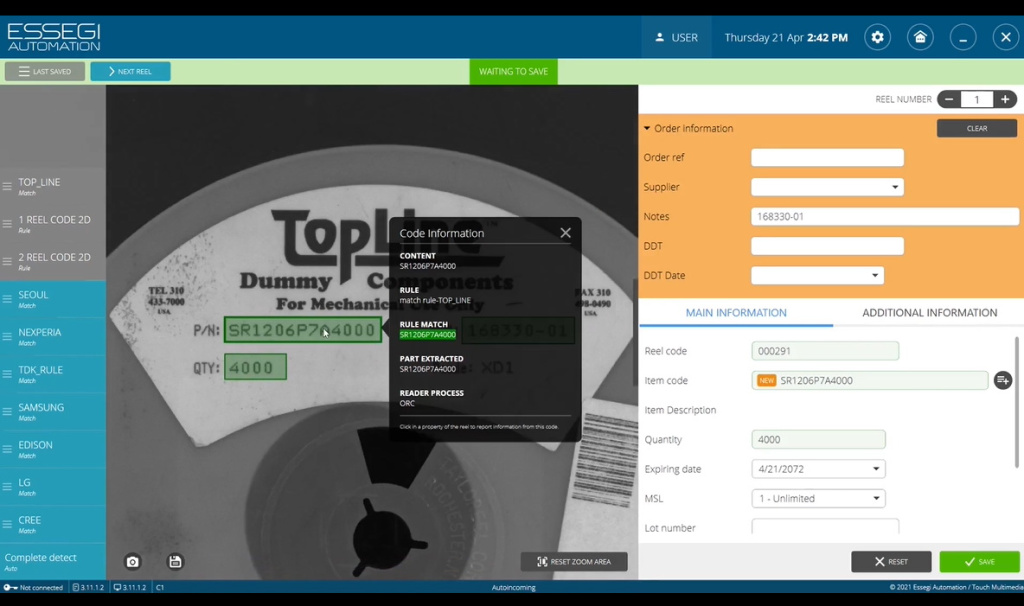
Рисунок 13
Чтение информации с QR-кода
Еще один пример - это пример этикетки с QR-кодом (Рисунок 14). QR-код как правило содержит и информацию о названии компонента, информацию о количестве, также может содержать какую-то дополнительно формацию, например, класс влагочуствительности и так далее. Мы точно также можем создать правило импорта и считывать информацию с QR-кода в соответствующие поля ввода автоматически.
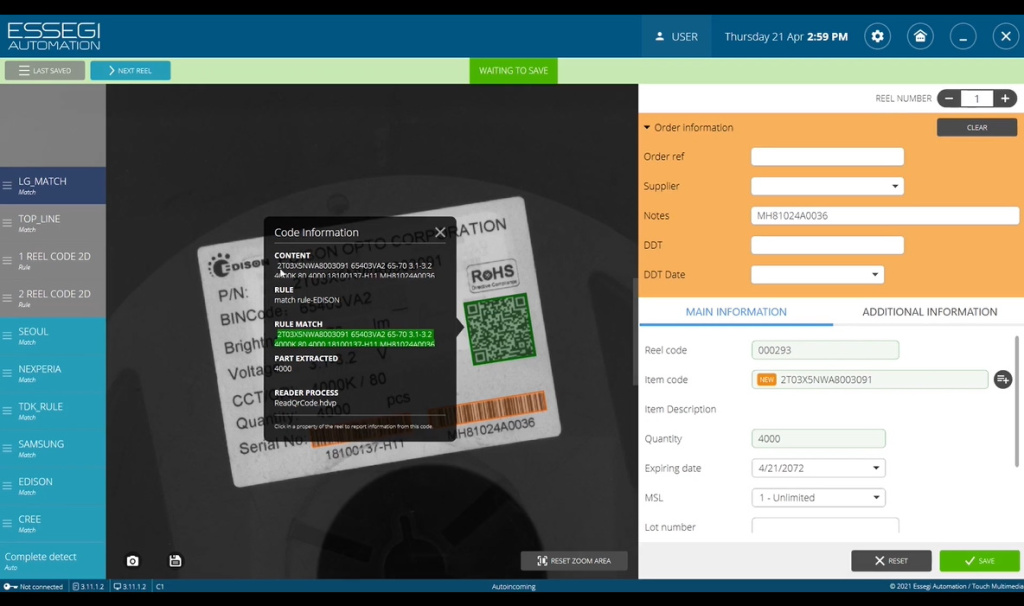
Рисунок 14
Сверка информации в процессе регистрации компонентов
Опционально можно сверять информацию из заказ-нарядов, либо полученную из ERP-системы предприятия с информацией, считываемой в процессе регистрации катушек. Для этого используются специализированный программный модуль, где содержится вся информация о номерах заказ-нарядов, к которым привязаны определенные названия и количество компонентов, которые необходимо зарегистрировать системе (Рисунок 15).
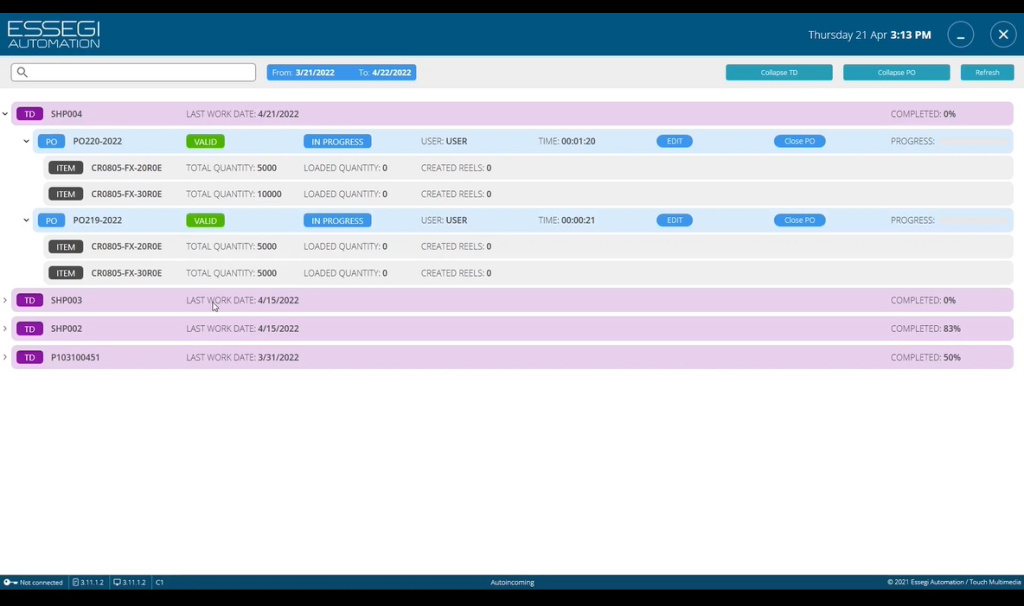
Рисунок 15
Как работает модуль? В процессе регистрации катушки и анализа информации с этикетки, мы считываем название компонента и его количество, которое содержится в конкретной регистрируемой катушке. Также мы указываем в процессе регистрации номер заказ-наряда, с которым производим сверку и каждый раз, регистрируя новую катушку, мы считываем название и количество компонентов (Рисунок 16).
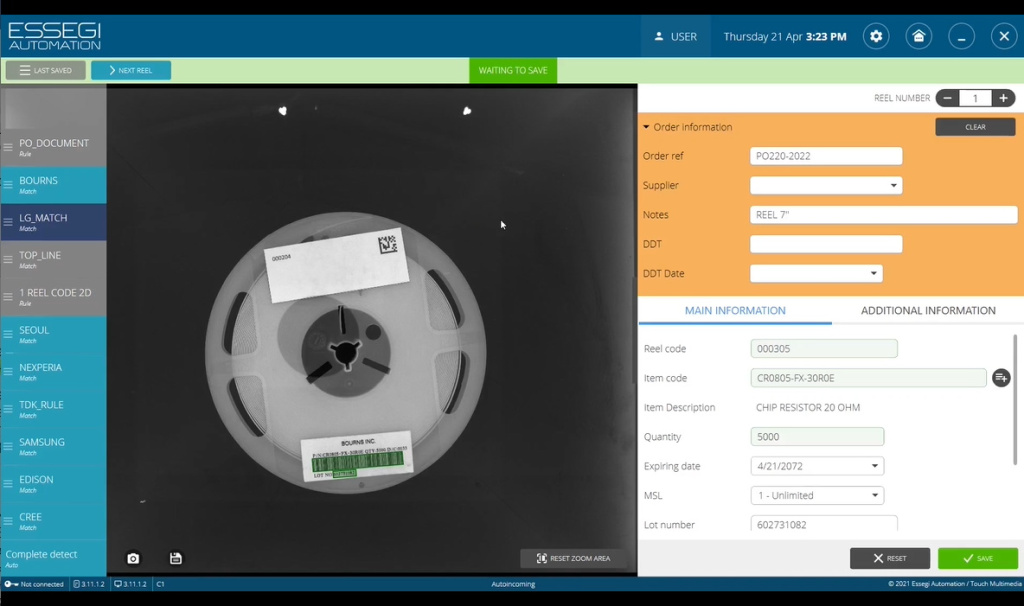
Рисунок 16
И данная считываемая с этикетки информации сверяется с той информацией, которая указана в заказ-наряде. В случае отсутствия ошибок система позволяет перейти к следующему шагу, то есть перейти к регистрации следующий катушки. В программном обеспечении это выражается в увеличении значения так называемого Progress bara, как показано на Рисунке 17, который постепенно от синего цвета перемещается к зеленому. Зеленый цвет означает, что все катушки с компонентов зарегистрированы без ошибок.
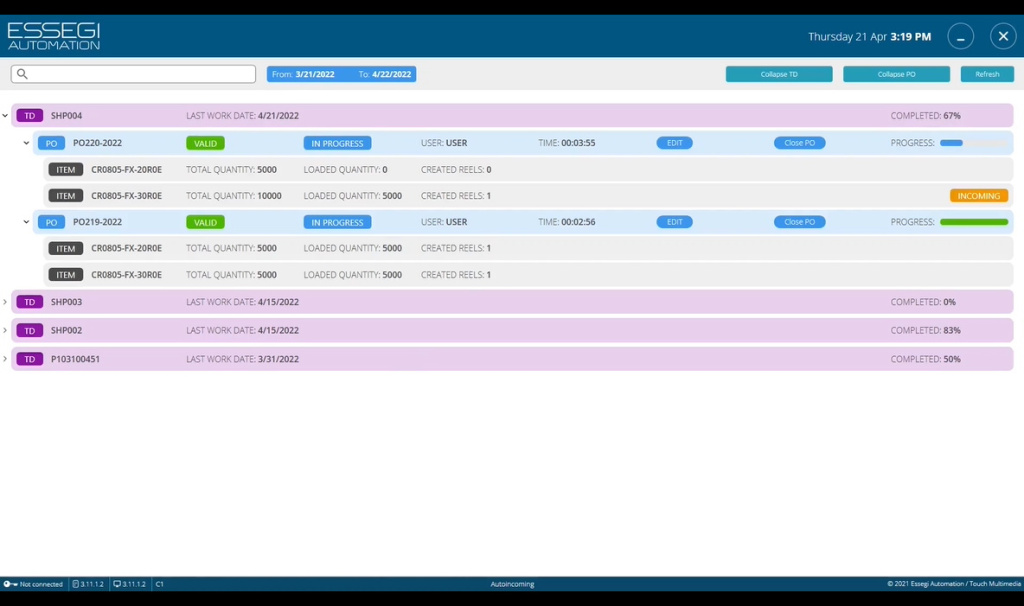
Рисунок 17
Мы рассмотрели работу станции регистрации компонентов. Если у вас остались вопросы, обращайтесь к специалистам Остек-СМТ, будем рады ответить на них и проконсультировать по вопросу приобретения оборудования.